Leetcode 2503. Maximum Number of Points From Grid Queries
Table of Contents
題目資訊
- 題目編號: 2503
- 題目連結: Maximum Number of Points From Grid Queries
- 主題: Array, Two Pointers, Breadth-First Search, Union Find, Sorting, Heap (Priority Queue), Matrix
題目敘述
您得到一個大小為 $m \times n$ 的整數矩陣 grid 和一個大小為 $k$ 的數組 queries。
找到一個大小為 $k$ 的數組 answer,使得對於每個整數 queries[i],您從矩陣的左上角單元開始並重複以下過程:
- 如果
queries[i]嚴格大於當前所處單元的值,那麼如果是您首次訪問這個單元,您就能獲得一分,並且可以向四個相鄰方向中的任意一個移動:上、下、左和右。 - 否則,您無法獲得任何分數,並結束此過程。
在過程結束後,answer[i] 是您可以得到的最多分數。注意,對於每個查詢,您可以多次訪問同一個單元。
請返回結果數組 answer。
範例 1:
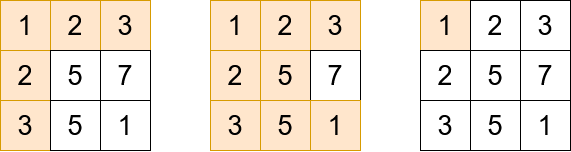
輸入: grid = [[1,2,3],[2,5,7],[3,5,1]], queries = [5,6,2]
輸出: [5,8,1]
解釋: 上圖顯示了我們為每個查詢獲得分數時訪問的單元格。
範例 2:
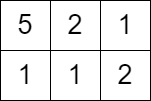
輸入: grid = [[5,2,1],[1,1,2]], queries = [3]
輸出: [0]
解釋: 我們無法獲得任何分數,因為左上角單元的值已經大於或等於 3。
約束條件:
- $m == \text{grid.length}$
- $n == \text{grid}[i].\text{length}$
- $2 \leq m, n \leq 1000$
- $4 \leq m \times n \leq 10^{5}$
- $k == \text{queries.length}$
- $1 \leq k \leq 10^{4}$
- $1 \leq \text{grid}[i][j], \text{queries}[i] \leq 10^{6}$
直覺
這個問題要求我們在遍歷從網格的左上角開始時,計算可以累積多少點數,條件是每次訪問單元格時,查詢的值必須大於該單元格的值,才能獲得一個點。目標是找出對於每個查詢通過有效遍歷能夠獲得的最大點數。
這個過程類似於在由網格表示的圖中進行搜索,其中每個單元格是連接到相鄰單元格的節點。因此,基於優先級的搜索演算法適合用來確保我們能高效地按值的遞增順序檢查單元格。
解法
這個演算法使用優先佇列來輔助遍歷網格,並考慮每個查詢。以下是逐步說明:
初始化:
- 建立一個
priority_queue來儲存按值優先排列的單元格(使用負號來模擬 C++ 的最大堆使其成為最小堆)。 - 初始化
visited用來標記已訪問的單元格。 - 準備一個單元素為零的
answerMemo向量來儲存預先計算的結果以供優化。
- 建立一個
起始點:
- 將網格的左上角單元格
(0, 0)插入priority_queue並標記為已訪問。
- 將網格的左上角單元格
處理每個查詢:
- 對於每個查詢,確保
answerMemo有足夠的條目來對應於查詢值。如果不夠,使用priority_queue的值來擴展answerMemo。 - 對於每個小於當前單元格值的查詢,從
priority_queue中彈出該單元格。- 如果單元格的值小於查詢值,則對應查詢的
answerMemo條目增加一。 - 檢查所有四個相鄰單元格;如果沒有被訪問過,則將其標記為已訪問,並推入
priority_queue。
- 如果單元格的值小於查詢值,則對應查詢的
- 對於每個查詢,確保
儲存結果:
- 將計算的結果(來自新計算的值或
answerMemo)存入answer向量。
- 將計算的結果(來自新計算的值或
輸出結果:
- 返回包含每個查詢的最大點數的
answer向量。
- 返回包含每個查詢的最大點數的
這種方法利用優先佇列動態計算最大可遍歷點數,使用鄰接考量來為每次查詢提供有效結果,而無需重複計算。
程式碼
C++
class Solution {
public:
vector<int> maxPoints(vector<vector<int>>& grid, vector<int>& queries) {
vector<int> answerMemo(1, 0), answer;
vector<vector<bool>> visited(grid.size(), vector<bool>(grid[0].size(), false));
priority_queue<pair<int, pair<int, int>>> priorityQueue;
int directions[] = {1, 0, -1, 0, 1}; // 移動方向: 右, 下, 左, 上。
int m = grid.size(), n = grid[0].size();
// 初始化起始點
priorityQueue.push({-grid[0][0], {0, 0}});
visited[0][0] = true;
// 處理每個查詢
for (int query : queries) {
// 如果查詢不在記錄中,根據需要擴展記錄
if (query >= answerMemo.size()) {
for (int i = answerMemo.size(); i <= query; i++) {
answerMemo.emplace_back(answerMemo.back());
// 處理優先隊列
while (!priorityQueue.empty() && -priorityQueue.top().first < i) {
auto [val, pos] = priorityQueue.top();
auto [x, y] = pos;
priorityQueue.pop();
// 增加當前閾值的點數
answerMemo[i]++;
// 檢查所有相鄰的格子
for (int j = 0; j < 4; j++) {
int next_x = x + directions[j], next_y = y + directions[j + 1];
if (next_x < 0 || next_y < 0 || next_x >= m || next_y >= n || visited[next_x][next_y])
continue;
visited[next_x][next_y] = true;
// 將相鄰格子推入優先隊列
priorityQueue.push({-grid[next_x][next_y], {next_x, next_y}});
}
}
}
}
// 根據查詢大小將計算出的點數追加到答案中
if (query >= answerMemo.size())
answer.emplace_back(answerMemo.back());
else
answer.emplace_back(answerMemo[query]);
}
return answer;
}
};
Python
from heapq import heappush, heappop
class Solution:
def maxPoints(self, grid, queries):
answerMemo = [0]
answer = []
visited = [[False] * len(grid[0]) for _ in range(len(grid))]
priorityQueue = []
directions = [1, 0, -1, 0, 1] # 移動方向:右,下,左,上。
m, n = len(grid), len(grid[0])
# 初始化起始點
heappush(priorityQueue, (-grid[0][0], (0, 0)))
visited[0][0] = True
# 處理每個查詢
for query in queries:
# 如果查詢不在備忘錄中,則根據需要擴展備忘錄
if query >= len(answerMemo):
for i in range(len(answerMemo), query + 1):
answerMemo.append(answerMemo[-1])
# 處理優先佇列
while priorityQueue and -priorityQueue[0][0] < i:
val, pos = heappop(priorityQueue)
x, y = pos
# 增加當前閾值的點數
answerMemo[i] += 1
# 檢查所有鄰近的單元格
for j in range(4):
next_x, next_y = x + directions[j], y + directions[j + 1]
if next_x < 0 or next_y < 0 or next_x >= m or next_y >= n or visited[next_x][next_y]:
continue
visited[next_x][next_y] = True
# 將鄰近的單元格推入優先佇列
heappush(priorityQueue, (-grid[next_x][next_y], (next_x, next_y)))
# 根據查詢大小將計算的點數附加到答案中
if query >= len(answerMemo):
answer.append(answerMemo[-1])
else:
answer.append(answerMemo[query])
return answer
複雜度分析
時間複雜度: $O(k \cdot \log(m \cdot n) + m \cdot n \cdot \log(m \cdot n))$。此複雜度來自於兩個主要過程:遍歷每個查詢並處理優先隊列。對於每個查詢,網格中可能有多達 $m \cdot n$ 個單元需要考慮,這些單元會被推入和彈出優先隊列。在優先隊列上的每個操作,包括推入和彈出,都需要 $O(\log(m \cdot n))$ 的時間。鑑於有 $k$ 個查詢,因此總複雜度由此而來。
空間複雜度: $O(m \cdot n + k)$。這種空間需求用於儲存
visited矩陣,用來追蹤每個單元在 $m \times n$ 網格中的訪問狀態,以及用於儲存每個查詢值結果的answerMemo陣列直至queries中的最大值。answer所需的額外空間貢獻 $O(k)$。
Disclaimer: All reference materials on this website are sourced from the internet and are intended for learning purposes only. If you believe any content infringes upon your rights, please contact me at csnote.cc@gmail.com, and I will remove the relevant content promptly.
Feedback Welcome: If you notice any errors or areas for improvement in the articles, I warmly welcome your feedback and corrections. Your input will help this blog provide better learning resources. This is an ongoing process of learning and improvement, and your suggestions are valuable to me. You can reach me at csnote.cc@gmail.com.